Language Model
ELMO
论文 Deep contextualized word representations 讨论了如何实现对不同的 token 产生不同的 embedding, 也就是 Contextualized Word Embedding.
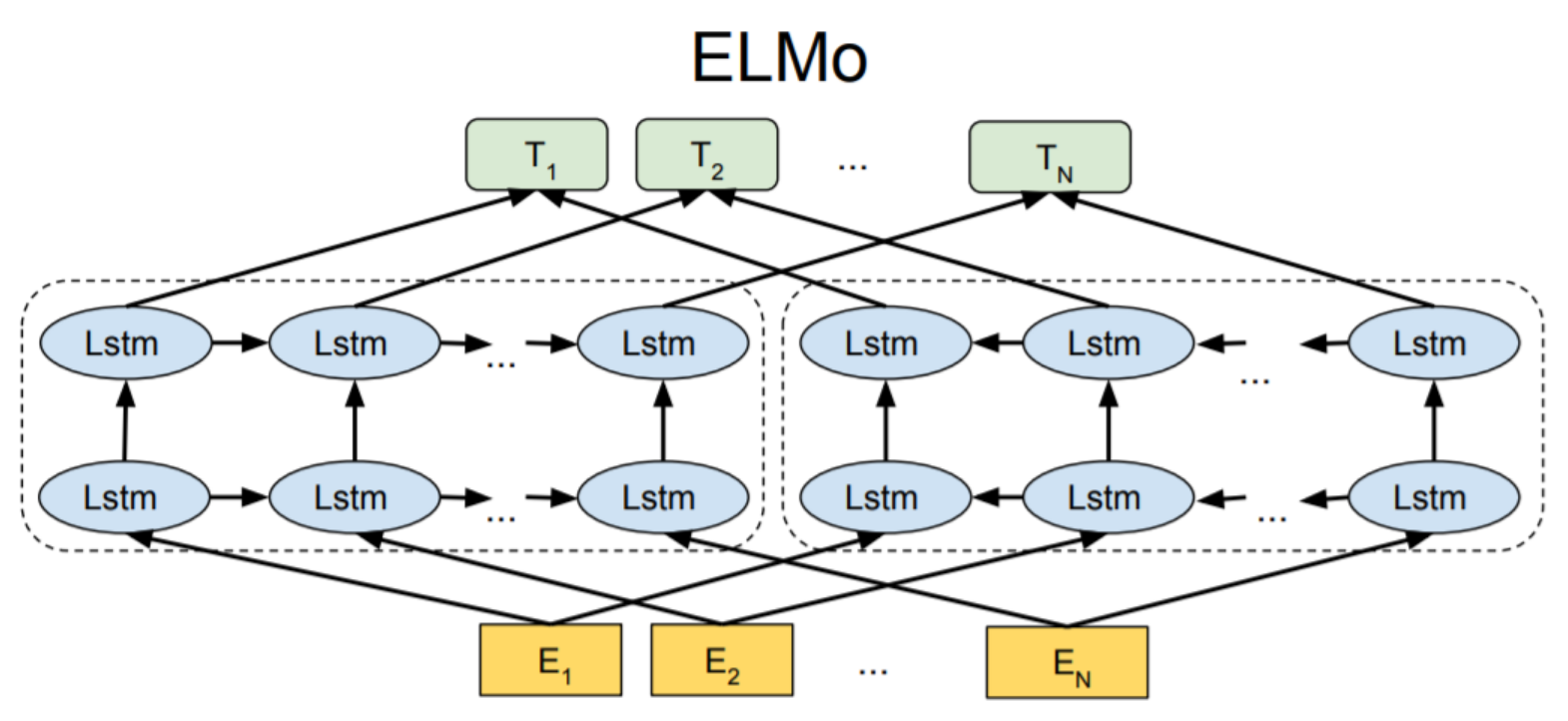
利用 LSTM 对句中的下一个词进行预测, 从而学习到该词的 embedding $E{left}$. 另一个方向的 LSTM 用后一个词预测前一个, 也得到一个 embedding $E{right}$. 并且每一层 LSTM 都会得到该词的 embedding, 最后加权求和得到最终 embedding.
BERT
BERT 的目标也是要学到 contextualized Word Embedding, 并且把 LSTM 换成 Transformer Encoder. 提出了 个 proxy task.
- Masked LM(完形填空): 将 token 用 [Mask] 替代, 然后将 embedding 送一个 classifier, 预测出 token
- Next Sentence Prediction: 将两个 sentences 放在一起, 判断是否相邻.
GPT
GPT-1
Improving Language Understanding by Generative Pretraining
Pretrain\
BERT 是 Transformer 的 Encoder, 而 GPT 是 Transformer 的 Decoder. 训练方式不太一样, GPT 是通过预测下一个词进行预训练的. 大家始终在说的的 Transformer 的 Encoder 和 Decoder 的区别是什么呢, Encoder 在抽取特征的时候能够看到整个序列的所有元素, Decoder 中因为存在掩码, 所以只能看到之前的元素.
则模型优化的目标可以表示为:
GPT 的引用没有 BERT 多, 一方面也是因为其选择的 Proxy Task 比 BERT 难, 训练起来更不容易. 但是这样比较困难的任务训练成功之后能到得到比 BERT 更强大的模型.
Finetune\
对于序列 $x^1, \cdots, x^m$ 和 Label $y$, $x^1, \cdots, x^m$ 输入 GPT 得到 $h_l^m$, 然后加上 Linear Layer $W_y$ 得到 prediction. 即:
如图所示, 在 Finetune 的过程中 $L_2(C)$ 对应 Task Classifier 的部分, 加上 Text Prediction 可以得到目标函数
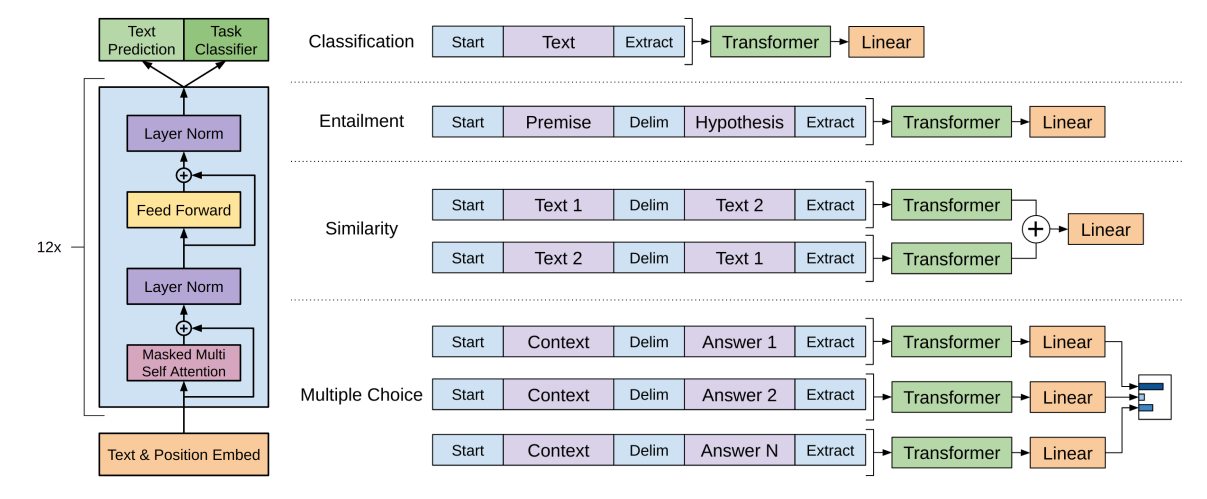
图2 中还展示了 GPT 对于不同 downstream task 需要做出的改变, 可以看到通常只需要改变输入内容而无需改变模型结构就可以适应各种任务. 这相比于之前的语言模型是重要的进步.
GPT-2
Language Models are Unsupervised Multitask Learners
之前说过 GPT-2 其实在同样参数量和数据量的情况下效果比不过 BERT, 因此 GPT-2 对 BERT 的回应是将 Zero-Shot 作为主要的买点. GPT-1 和 BERT 的使用方式都需要加入特殊的字符, 比如 [SEP], [MASK], [EXTRACT] 之类的. 有没有方法可以直接用自然语言告诉模型我们想要进行的是什么任务呢. 比如直接输入 ‘translate to english’ 让模型理解我们想要进行一个机器翻译的任务. 这种 Prompt 的方式也就是作者说的 Zero-Shot 的含义.
但是实验结果显示, GPT-2 在 downstream task 上的效果并不显著高于 BERT, 好消息是随着数据规模的增大, GPT 的提升并没有饱和.
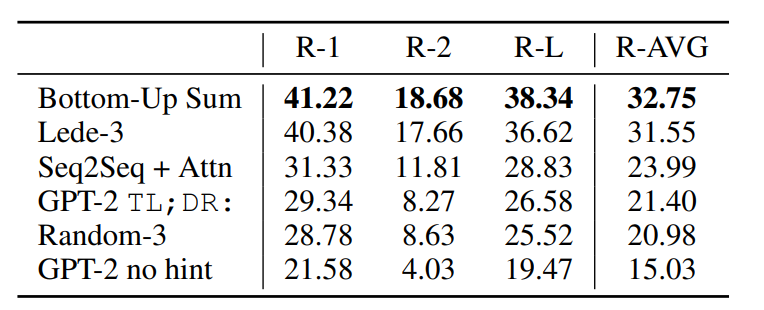
GPT-3
Language Models are Few-Shot Learners
GPT-2 为了追求新颖用了 Zero-Shot 的设置, 但是效果不是很突出, GPT-3 就是想解决这个问题. GPT-3 使用的 Few-Shot 的设置, 并且申明不需要在 downstream task 上做 finetune.
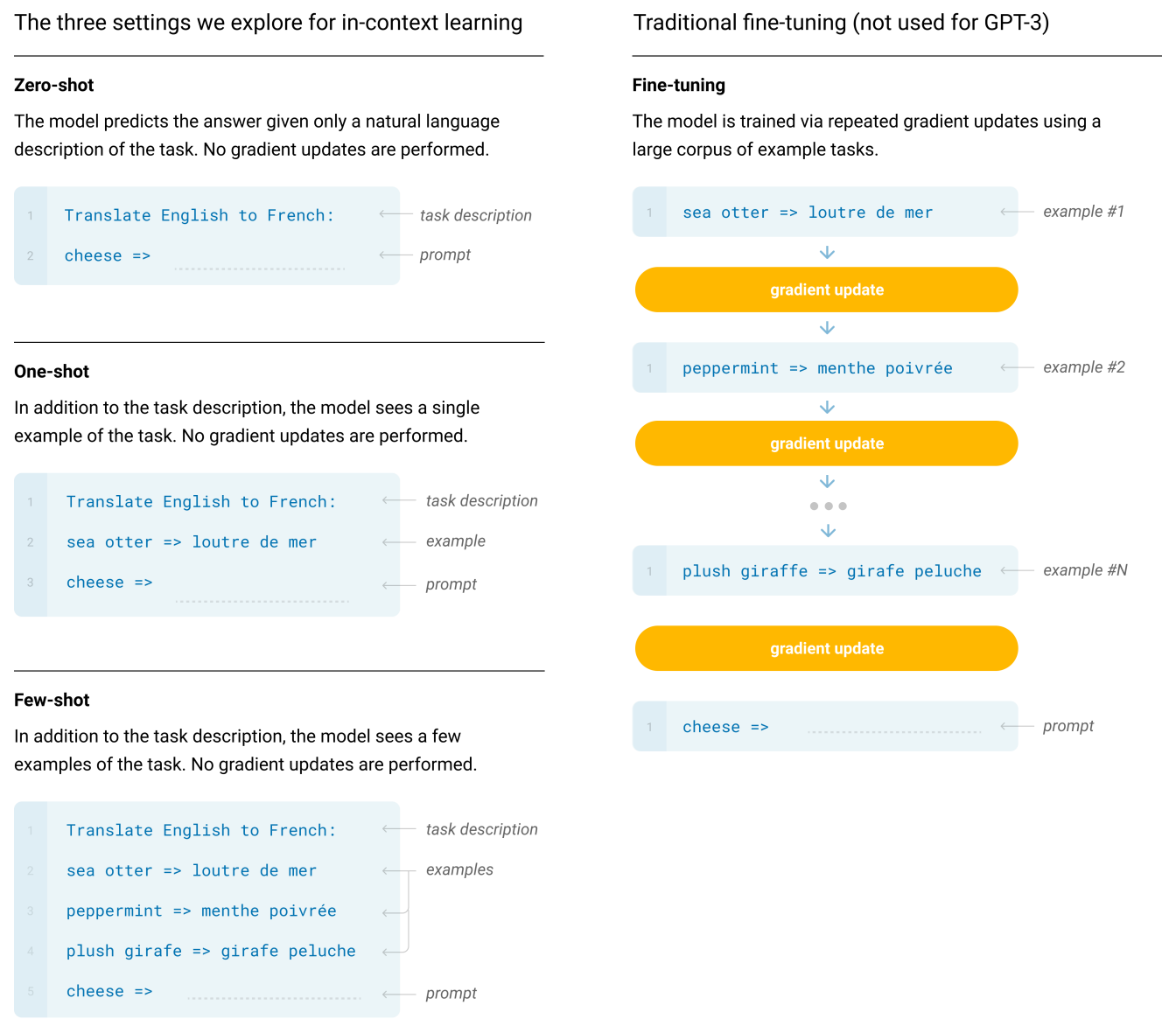
GPT-3 的文章写了 63 页, 特别长, 但是很多在讲自己的设定和实验结果.
首先讨论了为什么 GPT-3 不做 finetune: 标数据集要钱, 允许 fintune 不能说明预训练的泛化性好.
最后在讨论中说由于 GPT 的 Proxy Task 是预测下一个词, 所以无法表示单词之间的重要性(学了很多常见无意义的词).
此外作者还通过实验验证了 GPT-3 模型存在的性别、种族偏见等等.
Image GPT
Generative Pretraining from Pixels
Imgae GPT 就是把 Pixel 作为 sequence 输入, 别的和 GPT 区别不大.
在 Image 上训练 GPT 首先面临计算复杂度的问题, 每张图片的 sequence 长度为 2242243, 太大了.
所以先 downsample 再展开成 sequence. 这个欠采样也许是其在 downstream task 上的表现并不超级好的原因.
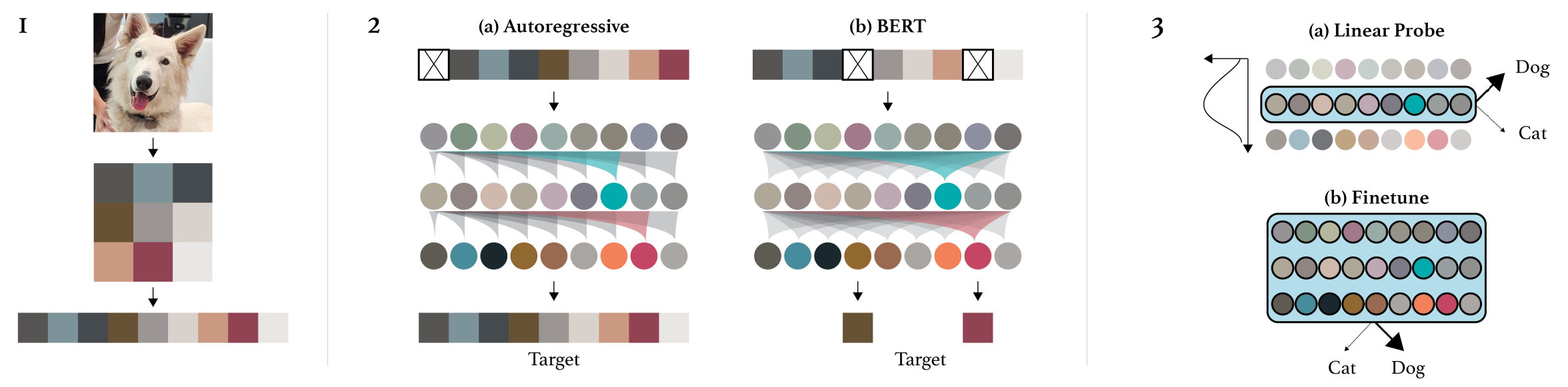
ImageGPT 进行对比的 baseline 之一, 也是一种进行 representation learning 的思路.
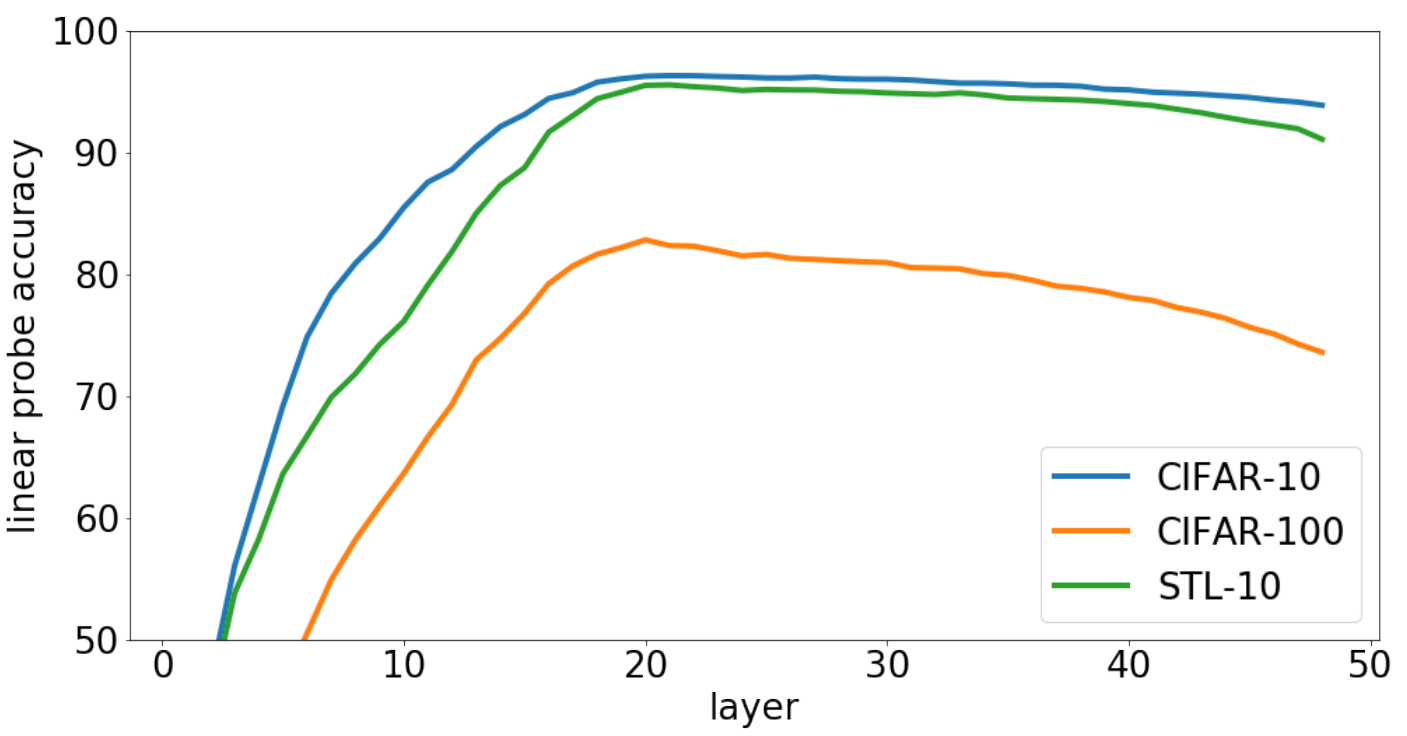
ImageGPT 和之前 NLP 中 GPT 都观察到的一个特征是中间层的 representation quality 比较高, 如图6. 所示. 一个可能的猜测是, 浅层 representation 比较 low-level, 靠后的 representation 与 proxy task 更接近, 不够 general.
参考资料:
