联邦学习(Naive 版)
本文为科普读物, 不构成任何学术观点, 欢迎指正.
Background
深度学习的各种方法都已经在大量场景中得到验证. 尽管如此, 他们存在一个突出的特征, 或者说缺点, 即对数据的依赖.
可以说从 2015 年前后爆发的深度学习浪潮是由数据集推动的, 其中久负盛名的有 MINIST, ImageNet 等等.
这些数据对深度学习方法提出了更大的挑战, 当新的方法被提出, 已有的数据集也就成为已经解决的问题, 这时研究者会思考如何构造更有挑战性的数据集, 进一步推动领域的发展.
然而对数据的收集并非易事. 对消费者来说, 隐私权不容侵犯, 众多包含敏感信息的数据一旦泄露将产生深远的负面影响. 如图1. 所示, 在一些社工库里面根据手机号码就可以查询到对应的姓名, 手机号, 身份证号, 电商购物记录, 社交媒体账号, 手机通讯录信息等等.
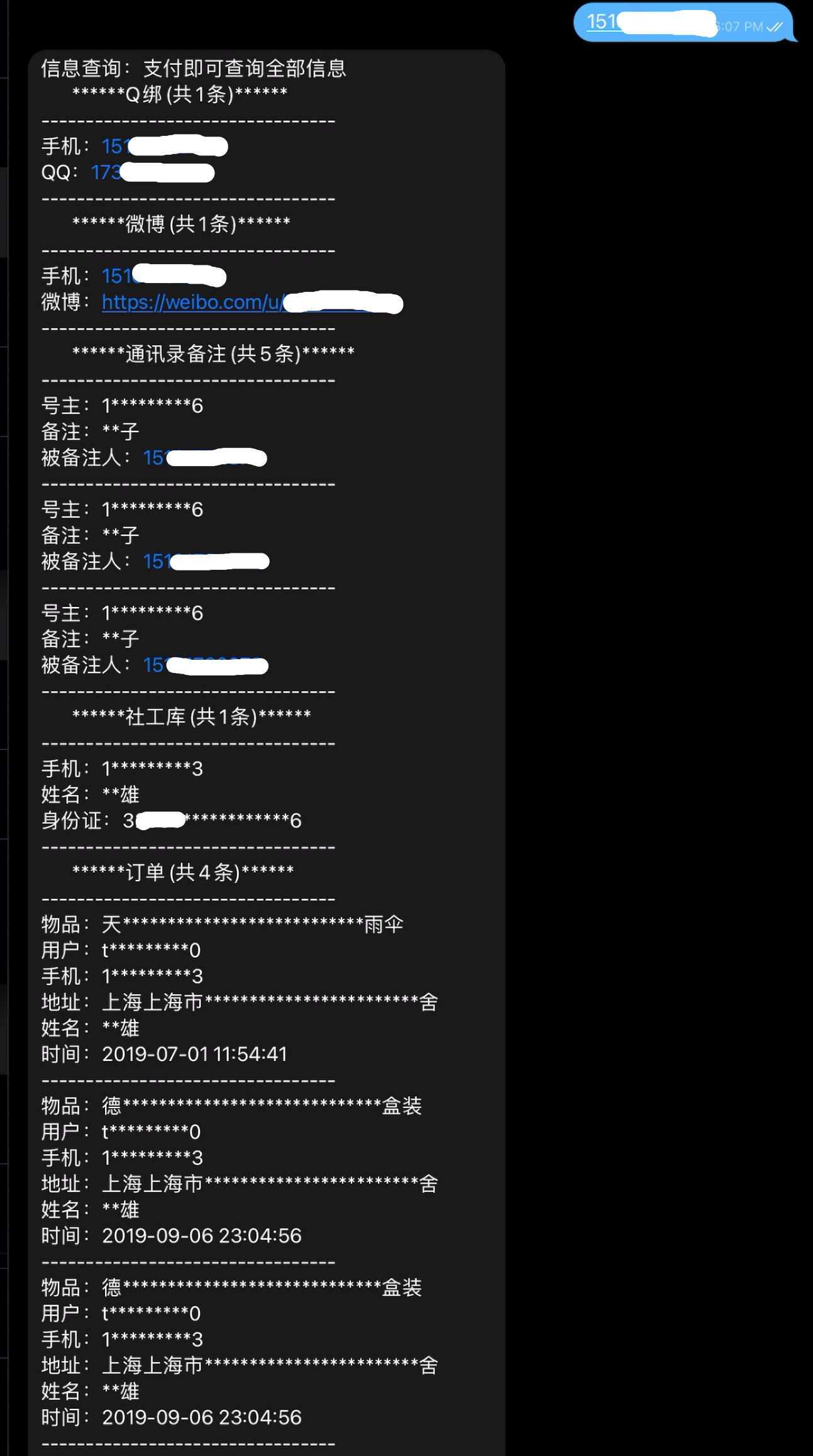
我们陷入两难, 不分析用户数据, 就无法提供个性化服务; 收集了数据可能泄露用户隐私. 有没有什么方法可以既利用数据带来的便利, 又保证信息安全呢. 联邦学习是一个可能的解.
除了电商之外, 很多金融机构也存在分析用户风险偏好的需求, 其涉及的数据更加私密敏感, 他们点亮了联盟链, 可信计算等科技树.
Introduction
联邦学习的核心思路是, 不传输数据, 只传输模型. 收集用户信息做机器学习存在风险, 那为什么不在本地训练, 然后直接上传模型呢. 如图2. 所示, 在用户的每个终端利用本地数据进行训练, 然后上传到云端进行集成.
通常机器学习模型比训练数据要小, 所以这样做还能节约带宽.
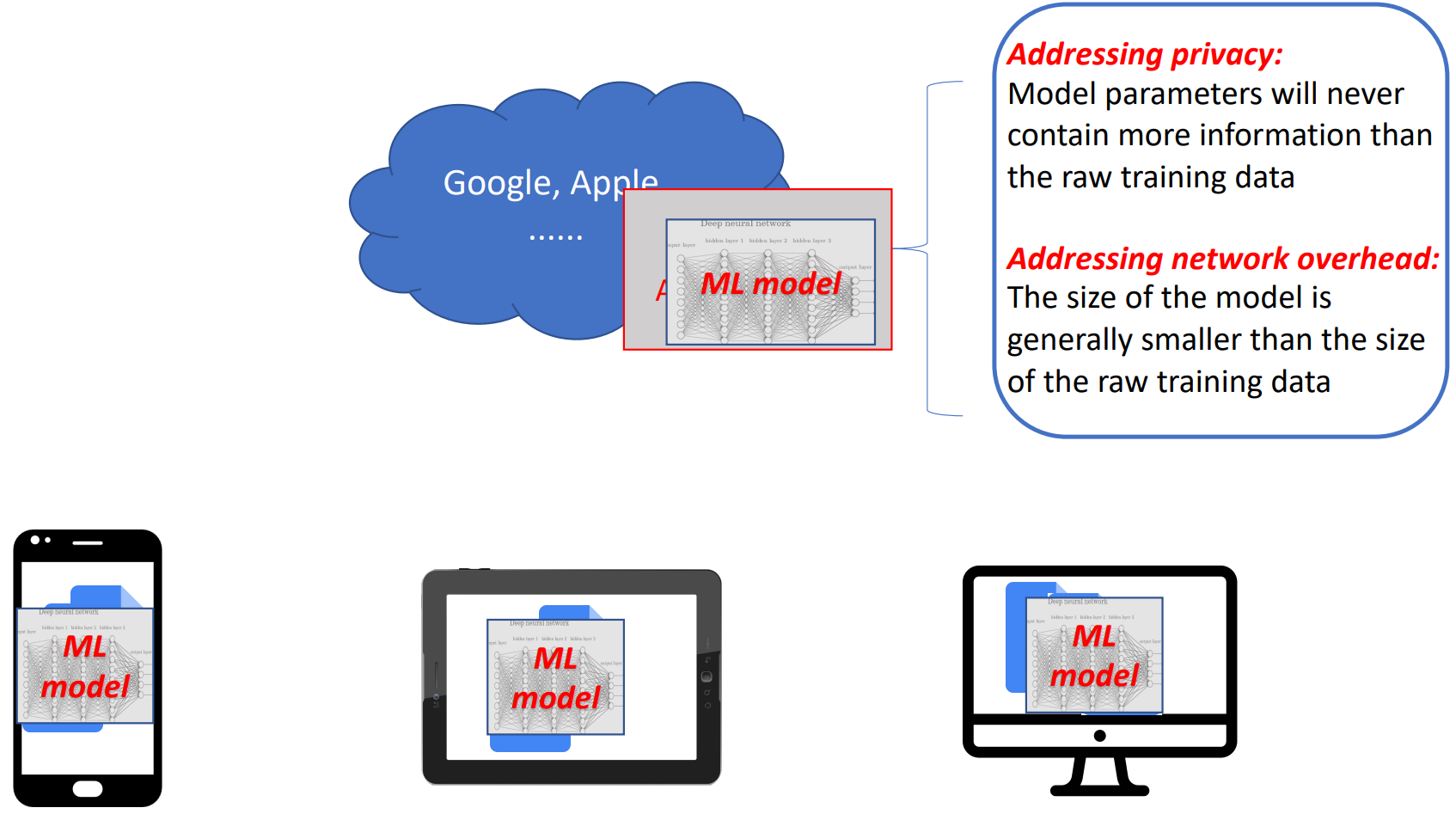
- Non-IID(Not identically and independently distributed): 不同用户数据不是独立同分布的
- Unbalenced: 不同用户产生的数据量很不一样
- Massively Distributed: 大量用户设备如何协同训练(19fall Android User: 2 billion)
- Limited Communication: 如何上传模型才不会影响用户体验
Related Works
这里并不是在严格地介绍联邦学习的相关工作, 更像是回忆我刚解除联邦学习时产生的一些疑问.
科学的发展是渐进的, 联邦学习不是被突然创造出来的, 其中 分布式学习(Distributed Learning) 可以说是其重要的基础之一.
在研究者开始考虑如何利用大量终端设备进行联邦学习之前, 就存在训练深度学习大模型的需求. 2021 年淘宝就有 3000万 用户, 他们每天产生 50TB 的数据. 如何利用如此大规模的数据构建模型, 用超级计算机吗?
答案是分布式. 如果一块硬盘存不下 50TB 数据, 那么就把数据分别存在不同的硬盘中好了; 如果一台电脑的算力不够, 那就让多台计算机分别计算部分数据的结果, 然后再汇总.
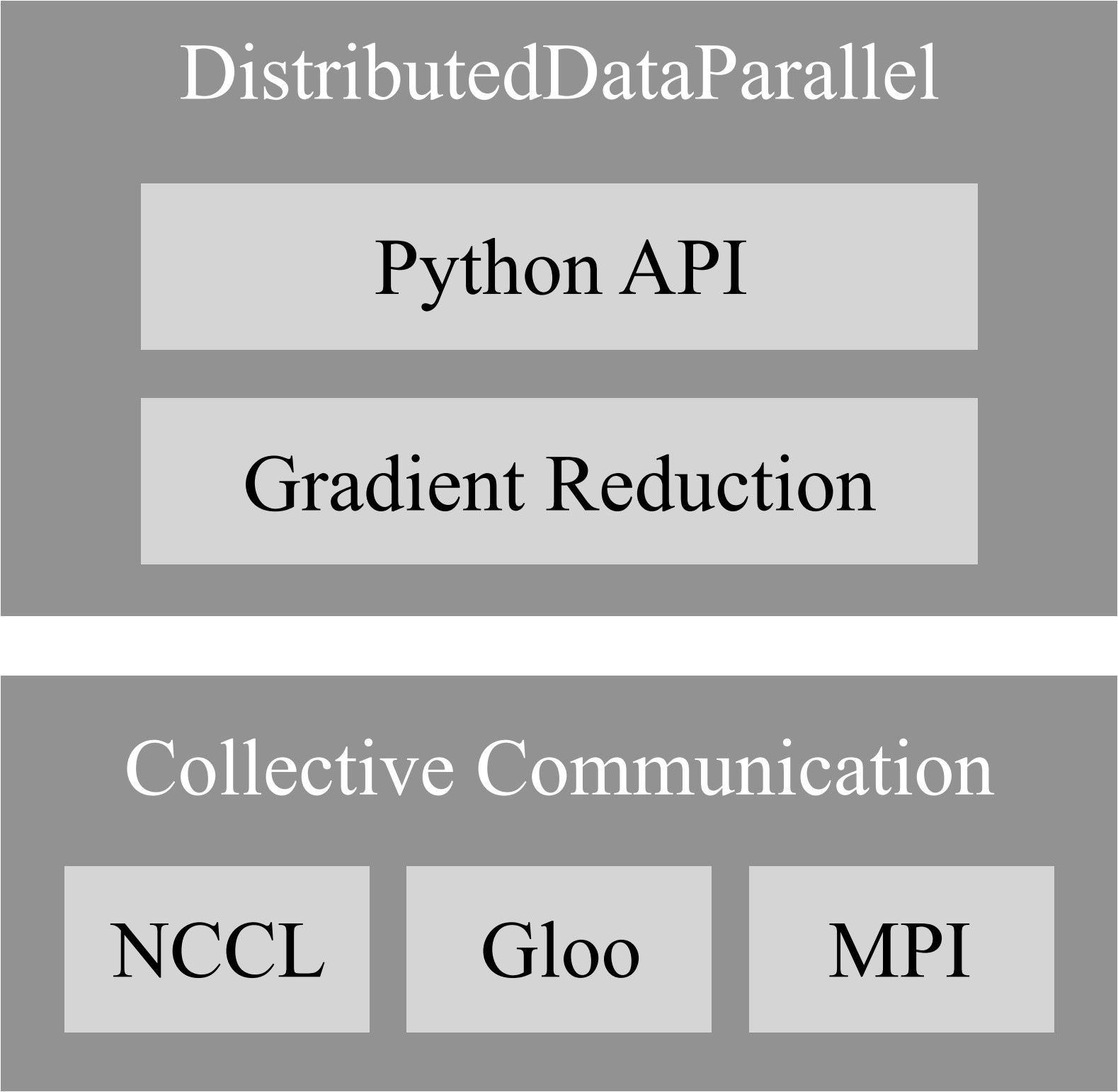
图3. 中展示的就是 Pytorch 对这一思想的实现结构. 之后有机会再详细介绍.
Methods
把每个参与联邦学习的企业称为参与方, 根据多参与方之间数据分布的不同, 把联邦学习分为三类
- 横向联邦学习(Horizontal FL)
- 纵向联邦学习(Vertical FL)
- 联邦迁移学习(Federated Transfer L)
Horizontal FL
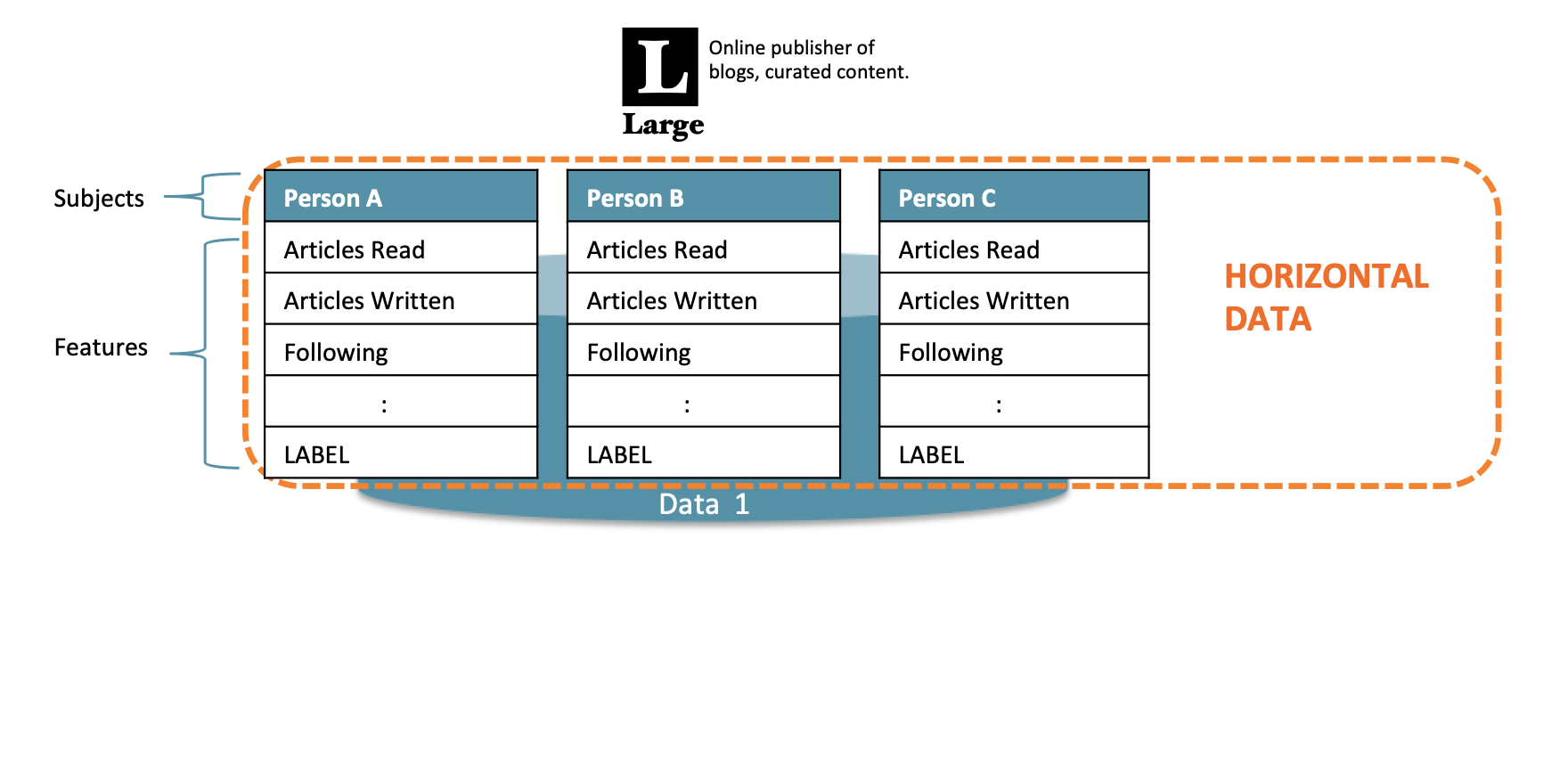
横向联邦学习的本质是样本的联合, 适用于参与者间业态相同但触达客户不同, 即特征重叠多, 用户重叠少时的场景, 比如不同地区的银行间, 他们的业务相似(特征相似), 但用户不同(样本不同)
Vertical FL
纵向联邦学习的本质是特征的联合, 适用于用户重叠多, 特征重叠少的场景, 比如同一地区的商超和银行, 他们触达的用户都为该地区的居民(样本相同), 但业务不同(特征不同).
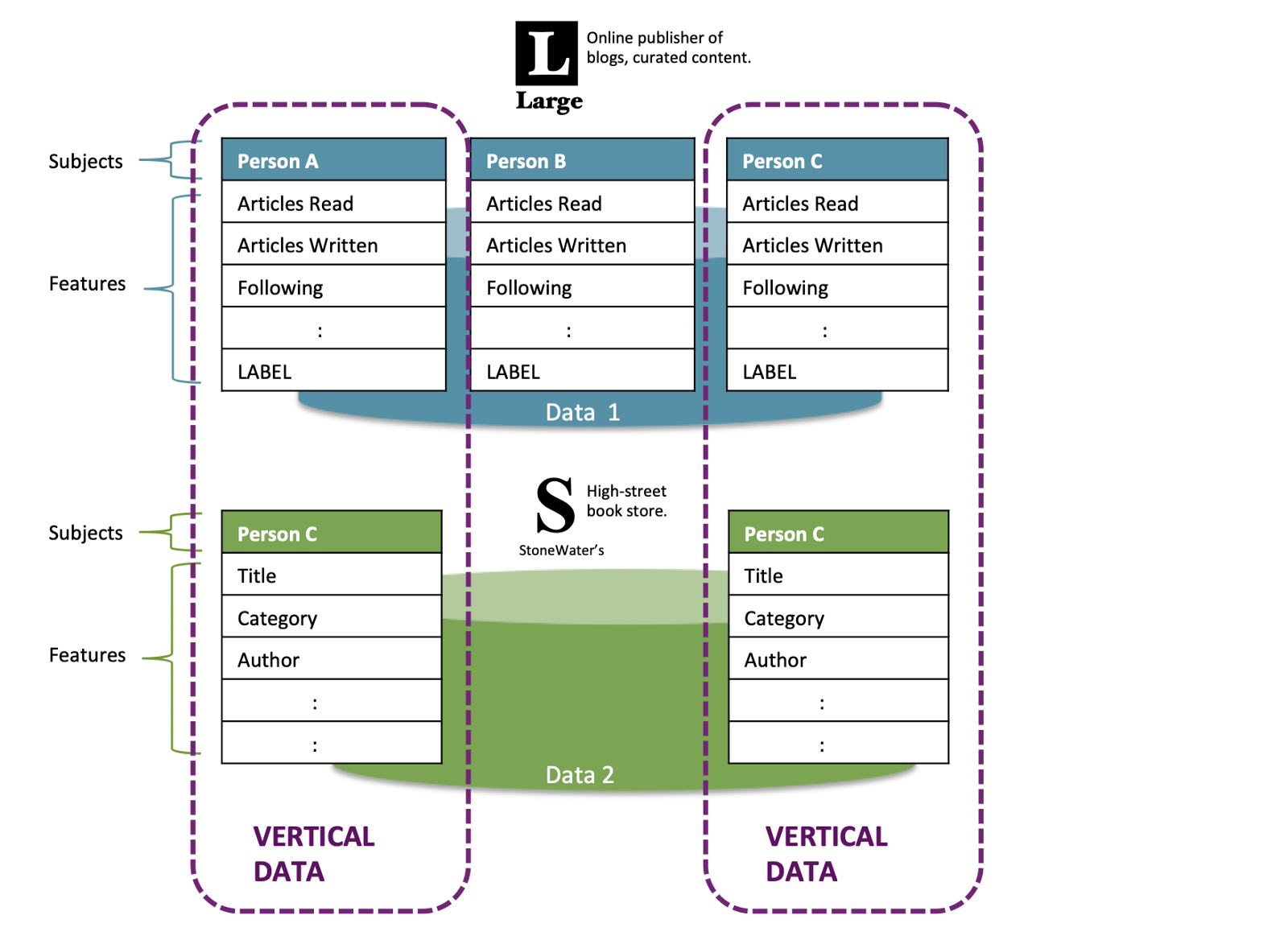
请读者思考, 我们的业务属于 Horizental ? Vertical FL.
Federared Transfer L
当参与者间特征和样本重叠都很少时可以考虑使用联邦迁移学习, 如不同地区的银行和商超间的联合. 主要适用于以深度神经网络为基模型的场景.
Conclusion
联邦学习受到热捧, 因为它提供了隐私的同时还能利用好数据带来的便利.
其适用的典型场景特征为
- 重视数据隐私, 安全性
- 终端设备多, 分布广
讨论
由时延带来的数据缺失
Q: 如果机器与分析中心时延大, 数据缺失将影响模型精度, 可以通过插值的方式对数据进行补全.
A: 我理解这个顾虑, 但是是否插值需要分情况讨论, 取决于该机器出错的模式.
以服务器的预测维修为例, 利用的是信号中的低频分量, 1s 内的实验都是可以接受的, 只要不宕机就行. 即便时延很低, 足够我们每秒钟采样 100 次, 我们也只好对这 100 次做平均. 毕竟我们需要的是低频分量.
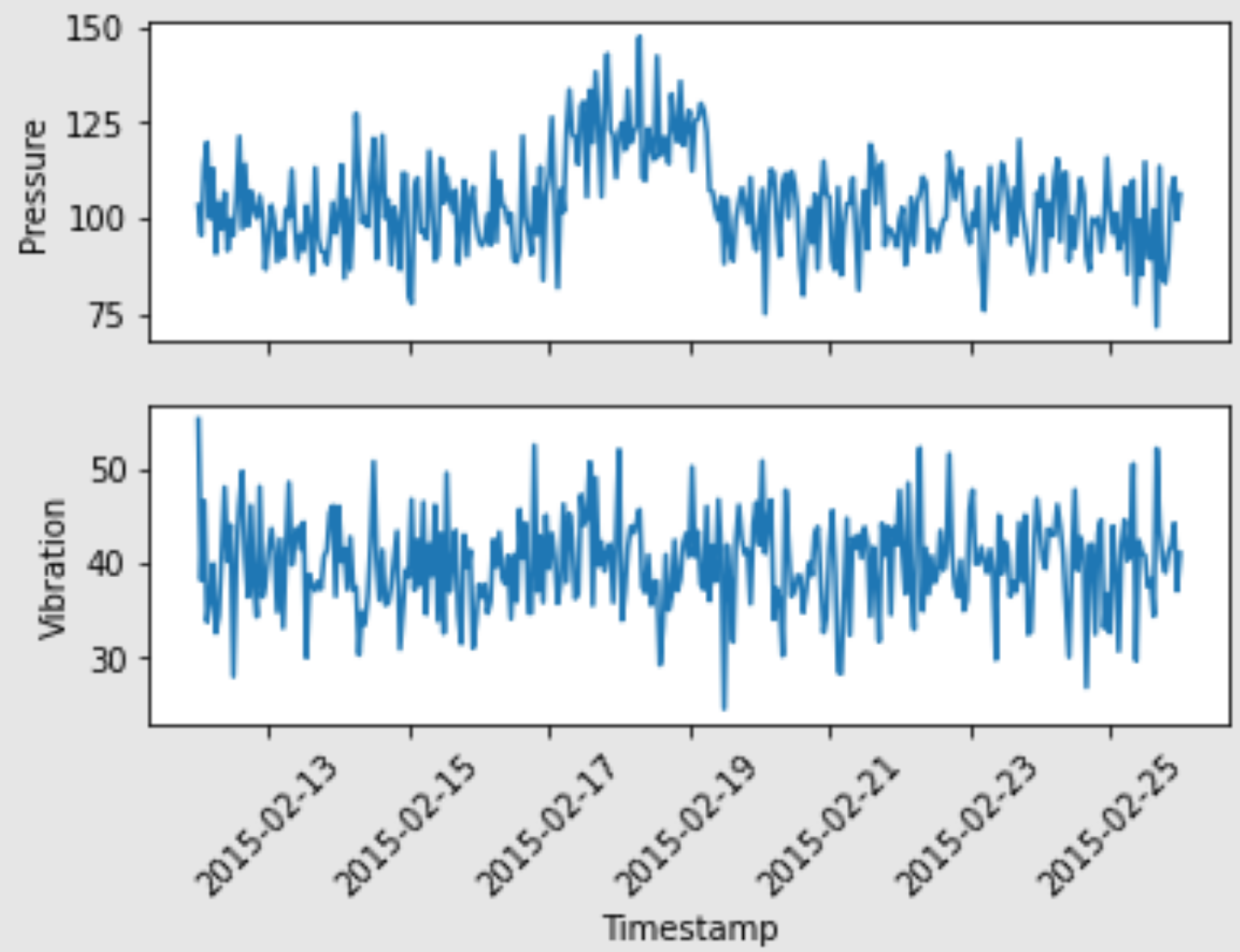
图6. 中是我对 Microsoft Azure 进行的分析, 微软工程师对一小时内的采样值进行平均, 可以看出故障不是在短时间内发生的, 暂时不必考虑时延.
